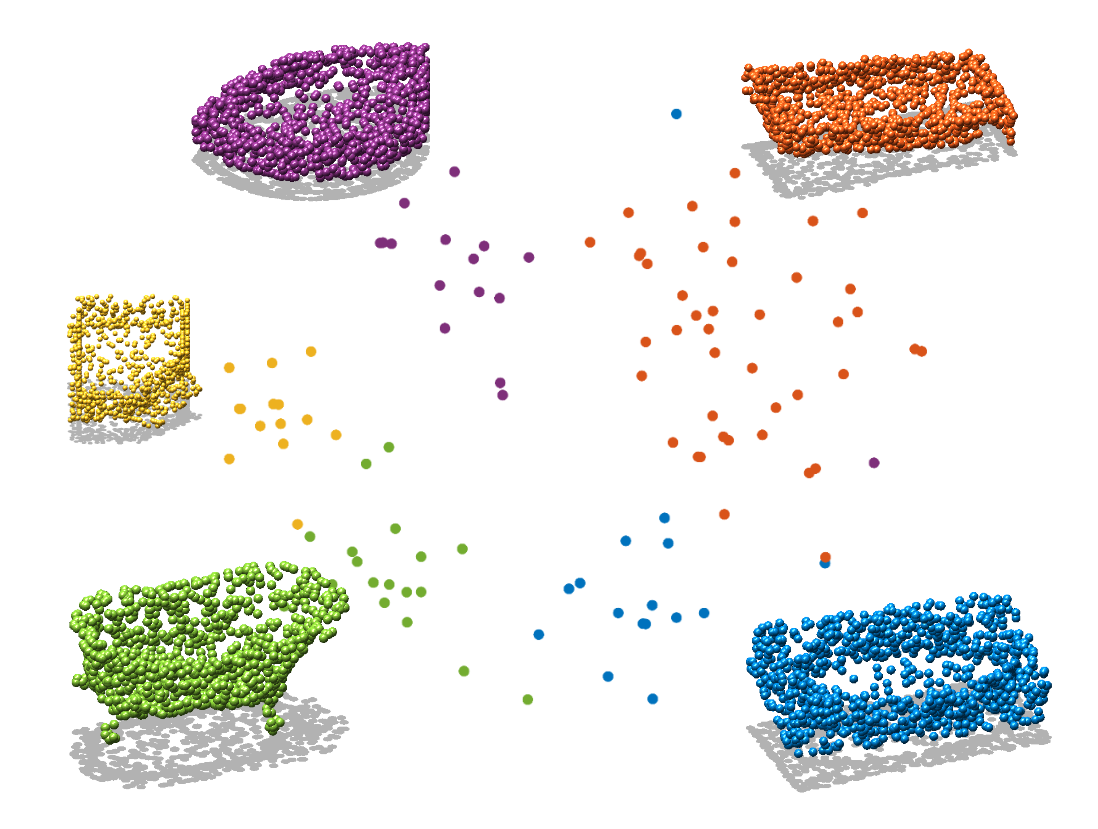
Bathtub

Bench

Chair
Flowerpot
Person

Cup
3D Vision-Language Foundation Models (VLFMs) have shown strong generalization and zero-shot recognition capabilities in open-world point cloud processing tasks. However, these models often underperform in practical scenarios where data are noisy, incomplete, or drawn from a different distribution than the training data.
To address this, we propose Uni-Adapter a training-free test-time adaptation method for 3D Vision-Language Foundation Models (VLFMs). It maintains a dynamic prototype cache that captures intra-class variability, applies graph-based label smoothing to enforce consistency among similar prototypes, and fuses predictions from both the VLFM and the cache using entropy-weighted aggregation. Without any retraining, Uni-Adapter significantly improves robustness, boosting performance by 10.55% on ModelNet-40C, 8.26% on ScanObjectNN-C, and 4.49% on ShapeNet-C.
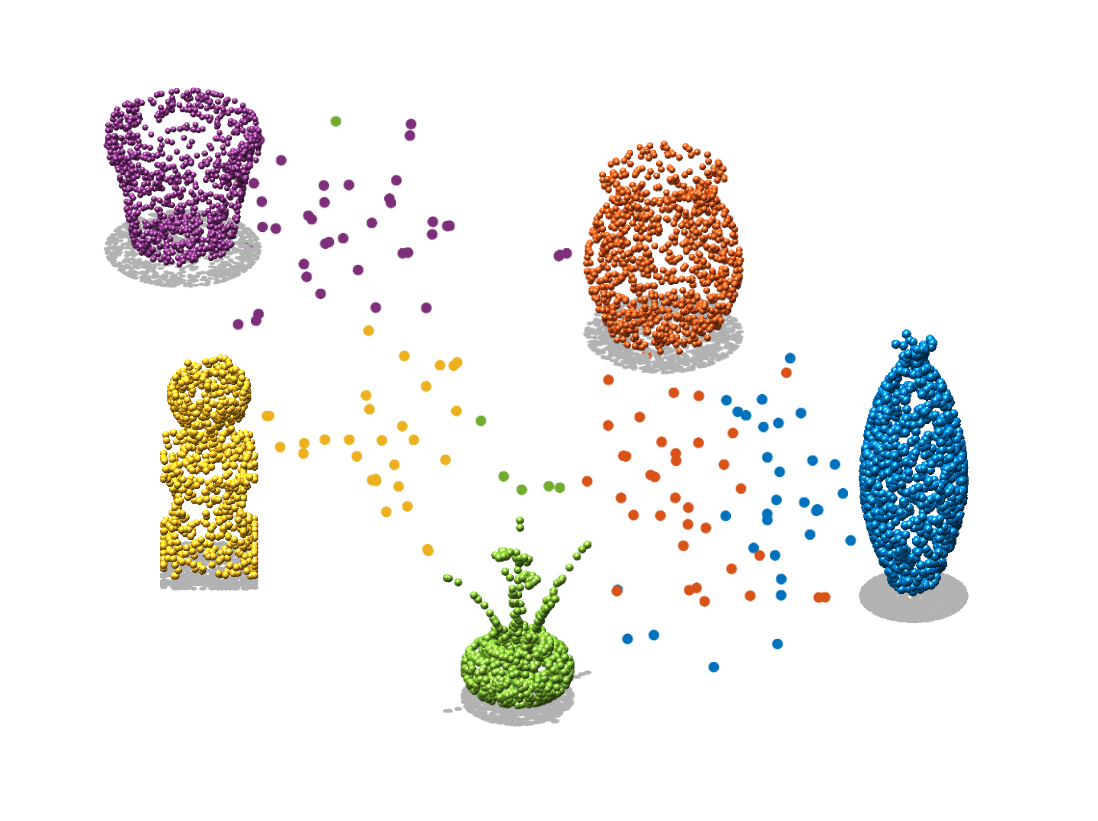
Bathtub
Bench
Chair
Flowerpot
Person
Cup
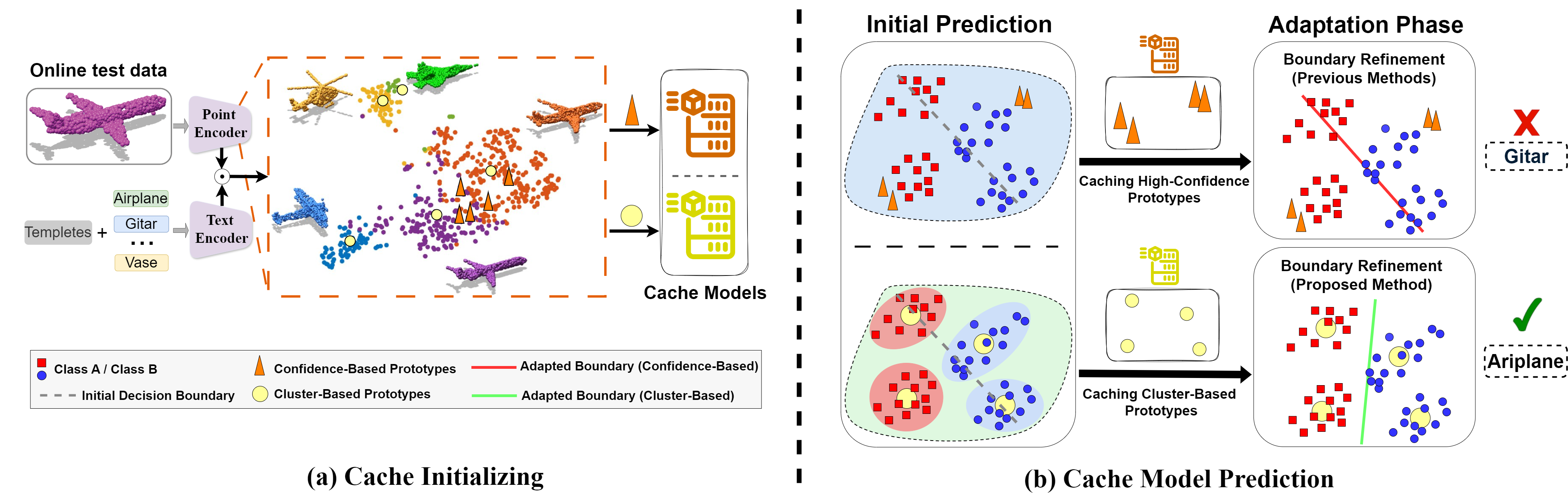
Figure 2. (a) t-SNE of Uni3D embeddings for the airplane class in ModelNet40-C shows clear intra-class clustering patterns.
Confidence-based prototypes (triangles) cache only high-confidence samples, while cluster-based prototypes (circles) represent
distribution modes via online clustering.
(b) In the toy example, confidence-based caching leads to incorrect boundaries due to poor mode coverage,
whereas cluster-based caching captures diverse patterns and enables correct predictions.
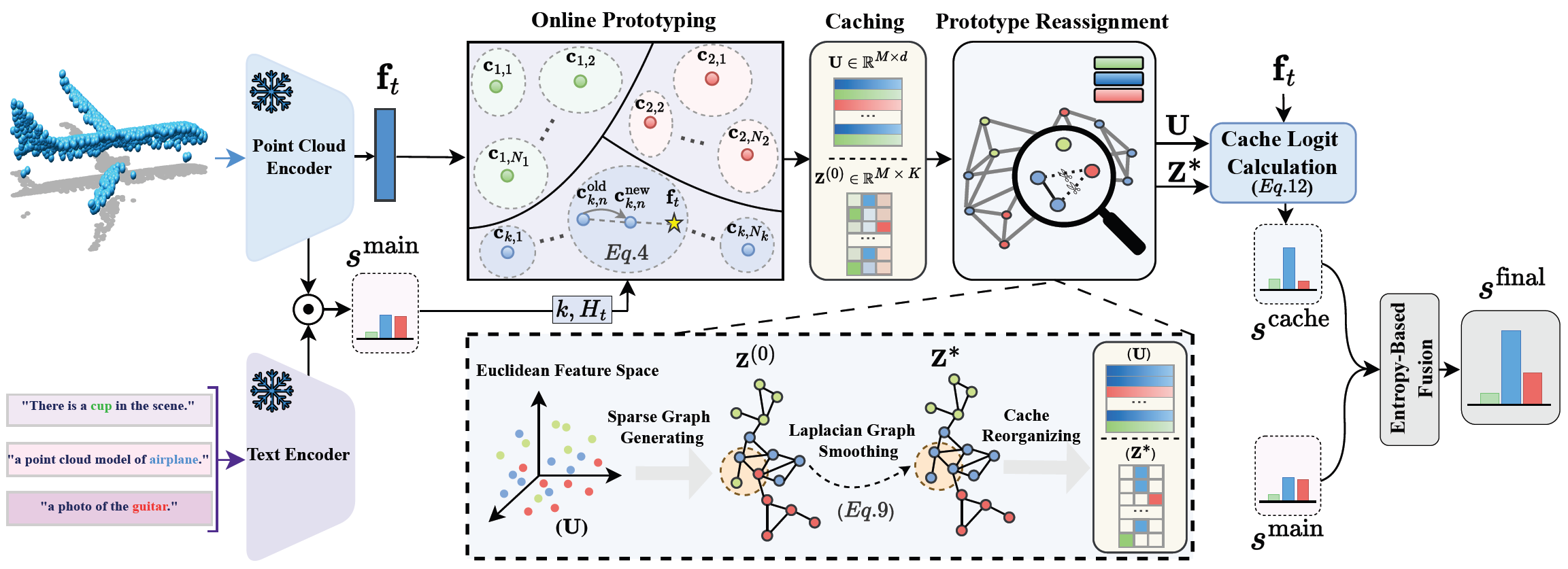
Figure 3. Method Overview. Given a test point cloud \( \mathbf{X}_t \in \mathbb{R}^{L \times 3} \), our method extracts a point cloud feature \( \mathbf{f}_t \) via a point cloud encoder. The 3D cache is updated through online Prototyping, where cluster centers serve as 3D prototypes. The Prototype Reassignment module refines these prototypes, and their affinity with \( \mathbf{f}_t \) produces \( \mathbf{s}^{\text{cache}} \). Finally, the prediction logit \( \mathbf{s}^{\text{final}} \) is obtained by fusing \( \mathbf{s}^{\text{cache}} \) with the model’s base output \( \mathbf{s}^{\text{main}} \) using entropy-driven confidence weighting.
.
We compare the throughput performance of Uni-Adapter against existing 3D VLFMs and cache-based approaches on the ModelNet40-C dataset. All results are obtained with batch size = 1 on an RTX 4090 GPU.
| Method | Uni3D | OpenShape | ULIP-2 |
|---|---|---|---|
| Zero-shot | 39.19 | 15.90 | 23.94 |
| TDA | 36.02 | 14.43 | 21.78 |
| Point-Cache | 9.73 | 9.74 | 11.11 |
| Uni-Adapter (Ours) | 36.93 | 15.06 | 22.67 |
| Method | uni | gau | bac | imp | ups | rbf | rbi | ded | dei | she | rot | cut | dis | ocl | lid | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source-Only | 57.37 | 54.01 | 70.21 | 61.91 | 60.69 | 51.74 | 52.39 | 67.50 | 74.87 | 72.40 | 71.02 | 63.97 | 58.95 | 47.24 | 22.93 | 59.15 |
| TENT (ICLR21) | 61.46 | 58.30 | 65.28 | 56.36 | 65.08 | 51.62 | 52.51 | 65.44 | 75.24 | 72.36 | 72.44 | 61.43 | 58.18 | 48.09 | 28.44 | 59.48 |
| SHOT (ICML20) | 61.50 | 58.42 | 65.27 | 56.68 | 64.66 | 51.54 | 52.84 | 65.48 | 75.57 | 72.81 | 72.29 | 61.14 | 58.14 | 48.46 | 28.44 | 59.55 |
| SAR (ICLR23) | 61.51 | 58.18 | 65.40 | 56.77 | 64.79 | 51.86 | 53.40 | 66.37 | 75.93 | 72.49 | 72.08 | 62.28 | 59.12 | 49.31 | 30.71 | 60.01 |
| DUA (CVPR22) | 61.26 | 57.90 | 65.11 | 56.76 | 64.79 | 51.38 | 53.08 | 65.44 | 75.16 | 72.93 | 72.41 | 60.85 | 58.35 | 48.50 | 28.65 | 59.50 |
| MEMO (NIPS22) | 57.38 | 54.08 | 70.24 | 61.92 | 60.71 | 51.76 | 52.39 | 67.59 | 74.88 | 72.48 | 71.03 | 63.98 | 59.30 | 47.36 | 22.94 | 59.20 |
| TPT* (NIPS22) | 60.65 | 57.20 | 76.32 | 61.15 | 63.47 | 55.39 | 55.78 | 71.36 | 74.77 | 75.20 | 73.01 | 65.41 | 60.97 | 47.60 | 18.10 | 61.02 |
| LAME (CVPR22) | 57.33 | 54.09 | 70.10 | 61.63 | 60.94 | 51.94 | 52.27 | 67.50 | 75.16 | 72.45 | 71.27 | 63.90 | 59.04 | 47.33 | 22.61 | 59.17 |
| 3DD-TTA (WACV25) | 60.53 | 59.76 | 63.53 | 64.71 | 67.91 | 50.73 | 51.09 | 59.36 | 66.98 | 64.26 | 58.67 | 59.36 | 53.77 | 36.10 | 32.37 | 56.06 |
| CloudFixer † (ECCV24) | 65.44 | 65.84 | 63.90 | 68.11 | 72.77 | 52.80 | 53.81 | 52.88 | 63.21 | 59.36 | 61.18 | 56.16 | 52.18 | 29.09 | 24.60 | 56.09 |
| T3A (NIPS21) | 69.40 | 70.26 | 41.89 | 63.33 | 70.74 | 61.26 | 59.27 | 72.20 | 79.33 | 77.59 | 78.36 | 71.07 | 65.51 | 49.59 | 32.01 | 64.12 |
| TDA* (CVPR24) | 62.20 | 61.63 | 75.16 | 65.52 | 67.18 | 57.46 | 57.94 | 70.95 | 76.94 | 74.43 | 73.26 | 67.46 | 63.17 | 50.69 | 30.39 | 63.63 |
| Point-Cache* | 64.34 | 64.87 | 73.95 | 68.31 | 71.68 | 62.84 | 65.19 | 73.22 | 77.80 | 77.15 | 75.77 | 69.77 | 68.31 | 54.78 | 32.98 | 66.73 |
| Uni-Adapter (Ours) | 66.82 | 65.52 | 78.32 | 72.25 | 72.04 | 65.60 | 66.61 | 77.51 | 80.63 | 79.05 | 79.30 | 75.29 | 73.38 | 56.92 | 36.26 | 69.70 |
| Method | uni | gau | bac | imp | ups | rbf | rbi | ded | dei | she | rot | cut | dis | ocl | lid | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source-Only | 60.33 | 55.75 | 65.95 | 65.02 | 59.04 | 59.41 | 60.23 | 79.06 | 71.07 | 75.62 | 73.87 | 76.82 | 63.22 | 2.37 | 1.06 | 57.92 |
| TENT (ICLR21) | 59.88 | 54.30 | 58.31 | 61.14 | 57.78 | 58.69 | 60.17 | 79.30 | 72.69 | 75.83 | 74.54 | 77.08 | 63.23 | 2.97 | 2.54 | 57.23 |
| SHOT (ICML20) | 59.96 | 54.32 | 58.37 | 61.14 | 57.67 | 58.81 | 60.19 | 79.23 | 72.53 | 75.90 | 74.57 | 77.09 | 63.34 | 3.02 | 2.51 | 57.24 |
| SAR (ICLR23) | 59.86 | 54.09 | 58.59 | 60.84 | 57.48 | 58.65 | 60.09 | 79.04 | 73.23 | 74.78 | 71.39 | 77.04 | 61.88 | 2.69 | 1.40 | 56.74 |
| DUA (CVPR22) | 59.85 | 54.37 | 58.26 | 61.21 | 57.89 | 58.71 | 60.15 | 79.11 | 72.40 | 72.55 | 75.91 | 77.05 | 63.24 | 2.97 | 2.53 | 57.08 |
| MEMO (NIPS22) | 60.33 | 55.76 | 66.02 | 65.02 | 59.04 | 59.42 | 60.23 | 79.01 | 70.92 | 75.62 | 73.95 | 76.82 | 63.22 | 2.41 | 1.09 | 57.92 |
| TPT* (NIPS22) | 62.87 | 56.63 | 69.20 | 64.70 | 59.10 | 58.29 | 60.43 | 81.59 | 75.23 | 76.93 | 74.56 | 80.52 | 63.02 | 2.17 | 1.25 | 59.10 |
| LAME (CVPR22) | 60.43 | 55.89 | 66.04 | 65.12 | 59.09 | 59.42 | 60.33 | 79.13 | 71.16 | 75.74 | 74.08 | 76.99 | 63.35 | 2.31 | 1.02 | 58.01 |
| 3DD-TTA (WACV25) | 65.78 | 64.16 | 55.00 | 61.75 | 68.05 | 55.06 | 56.20 | 74.20 | 67.35 | 68.06 | 61.19 | 73.01 | 56.29 | 2.50 | 0.97 | 55.30 |
| CloudFixer † (ECCV24) | 65.57 | 65.30 | 58.15 | 69.53 | 63.65 | 55.02 | 56.71 | 69.89 | 58.67 | 65.65 | 65.64 | 70.36 | 55.09 | 3.75 | 2.46 | 57.24 |
| T3A (NIPS21) | 60.60 | 53.12 | 20.70 | 44.19 | 49.31 | 46.35 | 44.37 | 70.31 | 63.01 | 64.86 | 63.83 | 68.24 | 52.60 | 1.00 | 0.87 | 46.89 |
| TDA* (CVPR24) | 62.75 | 58.95 | 68.33 | 67.14 | 62.09 | 61.28 | 62.56 | 79.00 | 71.44 | 75.93 | 74.79 | 77.17 | 64.44 | 3.82 | 1.81 | 59.43 |
| Point-Cache* (CVPR25) | 62.63 | 56.71 | 66.51 | 65.85 | 61.15 | 59.79 | 61.49 | 75.89 | 69.47 | 72.61 | 70.81 | 73.82 | 63.41 | 3.64 | 1.67 | 57.70 |
| Uni-Adapter (Ours) | 66.89 | 62.23 | 71.38 | 68.62 | 64.15 | 67.42 | 67.33 | 80.76 | 75.69 | 78.11 | 77.01 | 79.64 | 70.14 | 4.36 | 2.47 | 62.41 |
| Method | uni | gau | bac | imp | ups | rbf | rbi | ded | dei | she | rot | cut | dis | ocl | lid | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source-Only | 29.78 | 25.99 | 40.62 | 45.96 | 30.64 | 33.05 | 34.42 | 56.28 | 47.16 | 54.22 | 54.04 | 56.80 | 43.55 | 9.98 | 8.61 | 38.07 |
| TENT (ICLR21) | 29.78 | 26.16 | 49.91 | 51.46 | 30.65 | 33.22 | 36.32 | 55.08 | 45.27 | 52.50 | 53.18 | 55.77 | 44.92 | 7.06 | 3.79 | 38.34 |
| SHOT (ICML20) | 29.60 | 26.85 | 51.12 | 52.32 | 31.33 | 33.73 | 37.20 | 56.80 | 45.78 | 54.57 | 54.22 | 56.31 | 45.27 | 6.72 | 3.96 | 39.05 |
| SAR (ICLR23) | 29.08 | 27.54 | 42.17 | 44.58 | 31.33 | 32.36 | 34.77 | 56.28 | 44.41 | 52.84 | 54.22 | 55.59 | 44.06 | 9.64 | 9.64 | 37.90 |
| DUA (CVPR22) | 29.95 | 27.37 | 41.65 | 44.92 | 30.81 | 32.53 | 34.08 | 56.63 | 45.09 | 53.87 | 54.22 | 55.77 | 43.89 | 9.81 | 9.47 | 38.00 |
| MEMO (NIPS22) | 29.77 | 26.16 | 49.91 | 51.46 | 30.64 | 33.22 | 36.32 | 55.08 | 45.27 | 52.50 | 53.18 | 55.77 | 44.92 | 7.05 | 3.78 | 38.34 |
| TPT* (NIPS22) | 30.04 | 28.43 | 40.95 | 46.76 | 32.68 | 35.55 | 34.39 | 56.60 | 50.66 | 53.81 | 54.39 | 60.30 | 42.70 | 11.13 | 6.07 | 38.96 |
| LAME (CVPR22) | 29.60 | 26.85 | 51.12 | 52.32 | 31.33 | 33.73 | 37.18 | 56.80 | 45.78 | 54.56 | 54.22 | 56.29 | 45.27 | 6.71 | 3.96 | 39.05 |
| 3DD-TTA (WACV25) | 32.19 | 30.81 | 27.71 | 39.59 | 34.60 | 25.82 | 26.51 | 45.61 | 38.04 | 36.14 | 33.39 | 45.09 | 33.05 | 8.61 | 4.47 | 30.78 |
| CloudFixer † (ECCV24) | 36.83 | 33.22 | 36.14 | 48.19 | 37.69 | 27.54 | 30.46 | 45.44 | 40.28 | 38.73 | 38.21 | 46.13 | 35.28 | 10.67 | 11.70 | 34.43 |
| T3A (NIPS21) | 34.94 | 32.70 | 34.08 | 43.37 | 33.22 | 36.49 | 36.32 | 62.65 | 55.42 | 61.46 | 62.31 | 64.03 | 56.97 | 9.47 | 8.61 | 42.14 |
| TDA* (CVPR24) | 31.33 | 28.40 | 52.67 | 53.36 | 32.36 | 36.32 | 40.45 | 56.80 | 46.82 | 55.25 | 55.76 | 57.66 | 49.40 | 8.09 | 4.65 | 40.62 |
| Point-Cache* (CVPR25) | 30.98 | 27.19 | 55.25 | 56.45 | 33.73 | 40.79 | 43.03 | 59.50 | 49.23 | 60.07 | 56.63 | 57.66 | 49.05 | 8.26 | 4.30 | 42.13 |
| Uni-Adapter (Ours) | 35.28 | 37.69 | 53.35 | 59.55 | 39.07 | 42.16 | 52.49 | 60.58 | 51.97 | 61.61 | 60.24 | 60.92 | 54.38 | 20.82 | 4.81 | 46.33 |
@misc{tamjidi2025adaptasyouwalkcloudstrainingfreeonline,
title={Adapt-As-You-Walk Through the Clouds: Training-Free Online Test-Time Adaptation of 3D Vision-Language Foundation Models},
author={Mehran Tamjidi and Hamidreza Dastmalchi and Mohammadreza Alimoradijazi and Ali Cheraghian and Aijun An and Morteza Saberi},
year={2025},
eprint={2511.15311},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.15311},
}